







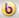


It’s somewhat ironic that I’m starting my second database programming related post with the same “I was looking for a certain solution but I couldn’t find any” passage. The difference is, this time it’s a problem more general than querying a weighted list: how to handle complex changes in a distributed database.
In the RDBMS world, a single transaction lets you do as many operations as you like, on as many tables or rows as you like. Lacking proper design and forward thinking though, more often than not this practice leads to hogging a significant portion of your resources.
Distributed databases can’t let this happen, so they introduce certain limitations to transactions. In Google App Engine (GAE) datastore for example, you can operate on rows of the same type having a common ancestor (rows, or entities as they’re called in GAE may have parent-children relationships ensuring that all entities on the same tree are stored on the same server). Bad design will still lead to problems (e.g. storing all your data on the same tree) but this way it’s your app that gets screwed not the database.
The lazy way
While this is generally good news, you’re faced with a new problem: handling changes that depend on the outcome of others. Here’s an example: you’re adding a new entry to the table (model in GAE) “grades” in a school database. You’ll have to keep the corresponding row, identified by the student, subject and semester, in the table “averages”, in sync. The lazy way of doing this would be performing the following steps in one transaction:
- Add row to grades
- Calculate new average
- Update average
‘By’ instead of ‘to’
There is a solution however, with two transactions, or more in more complex cases. In the last step of the above example, instead of changing the average (or rather the sum) to a certain value we’d change it by a certain value in a separate, “delta” transaction. The figure below demonstrates the difference between the two. At the top you see the timeline of two conventional transactions and below their overlapping delta equivalents.

Advantages of delta transactions:
- Isolated changes remain consistent.
- You can still roll back a batch of changes from code as delta transactions don’t care about subsequent changes as long as they are reversible and commutative.
- Using more, but shorter transactions (often operating on a single entity) there’s lower chance of concurrency.
- Even if concurrency occurs, fewer re-tries will be enough to avoid failure.
The obvious constraint to delta transactions is that they are only applicable to numeric values.
Support?
Considering how often this is needed, I was expecting some support for this kind of transactions in NoSQL based platforms. GAE features a method called get_or_insert() which is similar in a sense that it wraps a transaction that inserts the specified row (entity) before returning it, in case it doesn’t exist. But there could just as well be a method delta_or_insert(), that either inserts the specified row (entity) with the arguments as initial values if it doesn’t exist, or updates it with the arguments added, multiplied, etc. to the currently stored values.
Moreover, there could be support for rollback too, using delta transaction lists, and even the possibility to evaluate expressions only when they are needed would be a great one. Features like these that simplify transactions while increasing application stability and data integrity would be much appreciated I think by many developers new to these recent platforms.